与学习相关的技巧
前言
此为本人学习《深度学习入门》的学习笔记
一、参数的更新
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称为最优化(optimization)。为了找到最优参数,我们将参数的梯度(导数)作为了线索。使用参数的梯度,沿梯度方向更新参数,并重复这个步骤多次,从而逐渐靠近最优参数,这个过程称为随机梯度下降法(stochastic gradient descent),简称 SGD。
1、SGD
用数学式可以将 SGD 写成如下的式(6.1)
(6.1)
这里把需要更新的权重参数记为 W,把损失函数关于 W 的梯度记为 。η 表示学习率,实际上会取 0.01 或 0.001 这些事先决定好的值。式子中的←表示用右边的值更新左边的值。如式(6.1)所示,SGD 是朝着梯度方向只前进一定距离的简单方法。现在,我们将 SGD 实现为一个 Python 类
class SGD: def __init__(self, lr=0.01): self.lr = lr def update(self, params, grads): for key in params.keys(): params[key] -= self.lr * grads[key]
这里,进行初始化时的参数 lr 表示 learning rate(学习率)。这个学习率会保存为实例变量。此外,代码段中还定义了 update(params, grads) 方法,这个方法在 SGD 中会被反复调用。参数 params 和 grads(与之前的神经网络的实现一样)是字典型变量,按 params['W1']、grads['W1'] 的形式,分别保存了权重参数和它们的梯度。
使用这个 SGD 类,可以按如下方式进行神经网络的参数的更新
network = TwoLayerNet(...)optimizer = SGD()for i in range(10000): ... x_batch, t_batch = get_mini_batch(...) # mini-batch grads = network.gradient(x_batch, t_batch) params = network.params optimizer.update(params, grads) ...
SGD的缺点
SGD 的缺点是,如果函数的形状非均向(anisotropic),比如呈延伸状,搜索的路径就会非常低效。因此,我们需要比单纯朝梯度方向前进的 SGD 更聪明的方法。SGD 低效的根本原因是,梯度的方向并没有指向最小值的方向。
为了改正SGD的缺点,下面我们将介绍Momentum、AdaGrad、Adam这 3 种方法来取代SGD。
2、Momentum
Momentum 是“动量”的意思,和物理有关。用数学式表示 Momentum 方法,如下所示。
(6.3)
(6.4)
和前面的 SGD 一样,W 表示要更新的权重参数, 表示损失函数关于 W 的梯度,η 表示学习率。这里新出现了一个变量 v,对应物理上的速度。式(6.3)表示了物体在梯度方向上受力,在这个力的作用下,物体的速度增加这一物理法则。如图 6-4 所示,Momentum 方法给人的感觉就像是小球在地面上滚动。

图 6-4 Momentum:小球在斜面上滚动
式(6.3)中有 av 这一项。在物体不受任何力时,该项承担使物体逐渐减速的任务(α 设定为 0.9 之类的值),对应物理上的地面摩擦或空气阻力。下面是 Momentum 的代码实现
class Momentum: def __init__(self, lr=0.01, momentum=0.9): self.lr = lr self.momentum = momentum self.v = None def update(self, params, grads): if self.v is None: self.v = {} for key, val in params.items(): self.v[key] = np.zeros_like(val) for key in params.keys(): self.v[key] = self.momentum*self.v[key] - self.lr*grads[key] params[key] += self.v[key] 实例变量 v 会保存物体的速度。初始化时,v 中什么都不保存,但当第一次调用 update() 时,v 会以字典型变量的形式保存与参数结构相同的数据。剩余的代码部分就是将式(6.3)、式(6.4)写出来,很简单
3、AdaGrad
在关于学习率的有效技巧中,有一种被称为学习率衰减(learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多”学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。
AdaGrad 会为参数的每个元素适当地调整学习率,与此同时进行学习(AdaGrad 的 Ada 来自英文单词 Adaptive,即“适当的”的意思)。下面,让我们用数学式表示 AdaGrad 的更新方法。
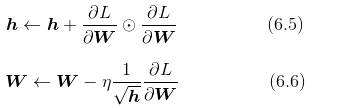
和前面的 SGD 一样,W 表示要更新的权重参数, 表示损失函数关于 W 的梯度,η 表示学习率。这里新出现了变量 h,如式 (6.5) 所示,它保存了以前的所有梯度值的平方和(式(6.5)中的
表示对应矩阵元素的乘法)。然后,在更新参数时,通过乘以
,就可以调整学习的尺度。这意味着,参数的元素中变动较大(被大幅更新)的元素的学习率将变小。也就是说,可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。
实现 AdaGrad。AdaGrad 的实现过程如下所示
class AdaGrad: def __init__(self, lr=0.01): self.lr = lr self.h = None def update(self, params, grads): if self.h is None: self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7) 需要注意的是,最后一行加上了微小值 1e-7。这是为了防止当self.h[key] 中有 0 时,将 0 用作除数的情况。在很多深度学习的框架中,这个微小值也可以设定为参数,但这里我们用的是 1e-7 这个固定值。
4、Adam
Momentum 参照小球在碗中滚动的物理规则进行移动,AdaGrad 为参数的每个元素适当地调整更新步伐。将二者融合在一起,就是Adam的基本思路。通过组合前面两个方法的优点,有望实现参数空间的高效搜索。此外,进行超参数的“偏置校正”也是 Adam 的特征。
Adam 会设置 3 个超参数。一个是学习率(论文中以 α 出现),另外两个是一次 momentum系数 β1 和二次 momentum系数 β2。根据论文,标准的设定值是 β1 为 0.9,β2 为 0.999。设置了这些值后,大多数情况下都能顺利运行。
5、更新方法的选择
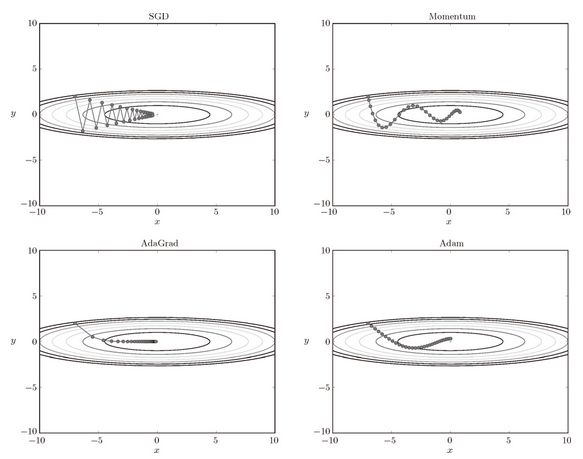
图 6-8 最优化方法的比较:SGD、Momentum、AdaGrad、Adam
目前,并不存在能在所有问题中都表现良好的方法。这 4 种方法各有各的特点,都有各自擅长解决的问题和不擅长解决的问题。很多研究中至今仍在使用 SGD。Momentum 和 AdaGrad 也是值得一试的方法。最近,很多研究人员和技术人员都喜欢用 Adam。
二、权重的初始值
1、可否将权重初始值设为0
权值衰减就是一种以减小权重参数的值为目的进行学习的方法。通过减小权重参数的值来抑制过拟合的发生。
如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上,在这之前的权重初始值都是像 0.01 * np.random.randn(10, 100) 这样,使用由高斯分布生成的值乘以 0.01 后得到的值(标准差为 0.01 的高斯分布)。
从结论来说,将权重初始值设为 0 不是一个好主意。事实上,将权重初始值设为 0 的话,将无法正确进行学习。
2、隐藏层的激活值的分布
观察隐藏层的激活值,
的分布,可以获得很多启发。这里,我们来做一个简单的实验,观察权重初始值是如何影响隐藏层的激活值的分布的。这里要做的实验是,向一个 5 层神经网络(激活函数使用 sigmoid 函数)传入随机生成的输入数据,用直方图绘制各层激活值的数据分布。

图6-10使用标准差为 1 的高斯分布作为权重初始值时的各层激活值的分布
从图 6-10 可知,各层的激活值呈偏向 0 和 1 的分布。这里使用的 sigmoid 函数是 S 型函数,随着输出不断地靠近 0(或者靠近 1),它的导数的值逐渐接近 0。因此,偏向 0 和 1 的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失(gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重。
下面,将权重的标准差设为 0.01,进行相同的实验。实验的代码只需要把设定权重初始值的地方换成下面的代码即可。
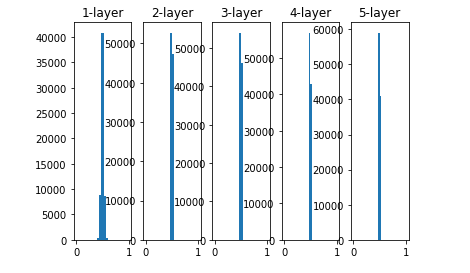
图 6-11 使用标准差为 0.01 的高斯分布作为权重初始值时的各层激活值的分布
这次呈集中在 0.5 附近的分布。因为不像刚才的例子那样偏向 0 和 1,所以不会发生梯度消失的问题。但是,激活值的分布有所偏向,说明在表现力上会有很大问题。因为如果有多个神经元都输出几乎相同的值,那它们就没有存在的意义了。比如,如果 100 个神经元都输出几乎相同的值,那么也可以由 1 个神经元来表达基本相同的事情。因此,激活值在分布上有所偏向会出现“表现力受限”的问题。
尝试使用 Xavier Glorot 等人的论文 [9] 中推荐的权重初始值(俗称“Xavier 初始值”)。现在,在一般的深度学习框架中,Xavier 初始值已被作为标准使用。比如,Caffe 框架中,通过在设定权重初始值时赋予 xavier 参数,就可以使用 Xavier 初始值。
Xavier 的论文中,为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度。推导出的结论是,如果前一层的节点数为 n,则初始值使用标准差为 的分布 {3[Xavier 的论文中提出的设定值,不仅考虑了前一层的输入节点数量,还考虑了下一层的输出节点数量。但是,Caffe 等框架的实现中进行了简化,只使用了这里所说的前一层的输入节点进行计算。]}(图 6-12)。
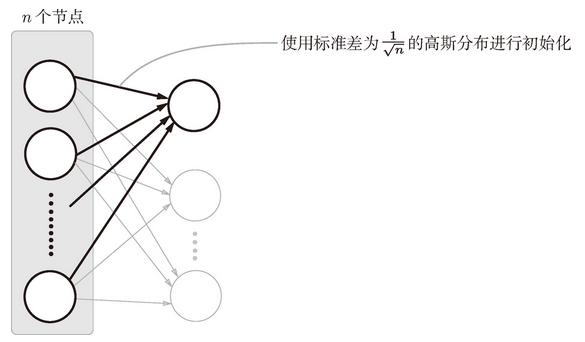
图 6-12 Xavier 初始值:与前一层有 n 个节点连接时,初始值使用标准差为 的分布
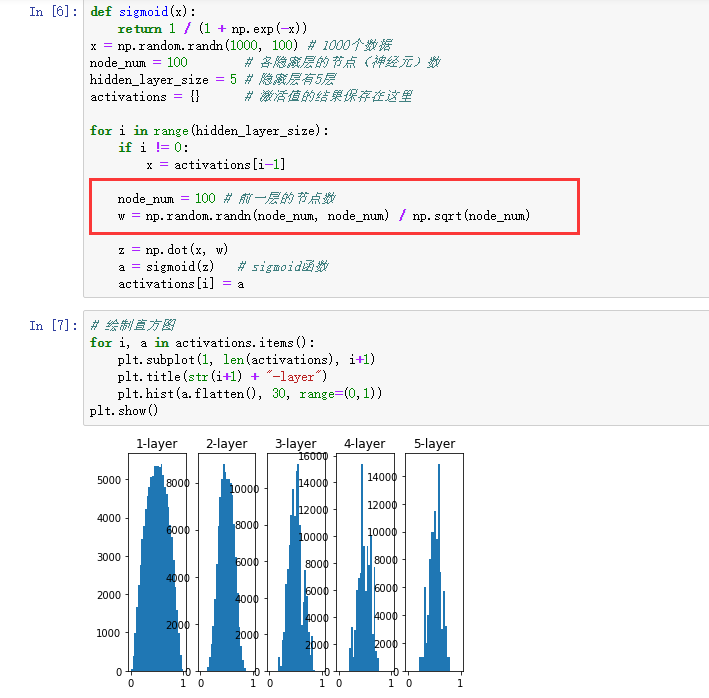
图 6-13 使用 Xavier 初始值作为权重初始值时的各层激活值的分布
使用 Xavier 初始值后的结果如图 6-13 所示。从这个结果可知,越是后面的层,图像变得越歪斜,但是呈现了比之前更有广度的分布。因为各层间传递的数据有适当的广度,所以 sigmoid 函数的表现力不受限制,有望进行高效的学习。
图 6-13 的分布中,后面的层的分布呈稍微歪斜的形状。如果用
tanh函数(双曲线函数)代替sigmoid函数,这个稍微歪斜的问题就能得到改善。实际上,使用tanh函数后,会呈漂亮的吊钟型分布。tanh函数和sigmoid函数同是 S 型曲线函数,但tanh函数是关于原点 (0, 0) 对称的 S 型曲线,而sigmoid函数是关于 (x, y)=(0, 0.5) 对称的 S 型曲线。众所周知,用作激活函数的函数最好具有关于原点对称的性质。
3、ReLU的权重初始值
Xavier 初始值是以激活函数是线性函数为前提而推导出来的。因为 sigmoid 函数和 tanh 函数左右对称,且中央附近可以视作线性函数,所以适合使用 Xavier 初始值。但当激活函数使用 ReLU 时,一般推荐使用 ReLU 专用的初始值,也就是 Kaiming He 等人推荐的初始值,也称为“He 初始值”[10]。当前一层的节点数为n 时,He 初始值使用标准差为 的高斯分布。当 Xavier 初始值是
时,(直观上)可以解释为,因为 ReLU 的负值区域的值为 0,为了使它更有广度,所以需要 2 倍的系数。
总结一下,当激活函数使用 ReLU 时,权重初始值使用 He 初始值,当激活函数为
sigmoid或tanh等 S 型曲线函数时,初始值使用 Xavier 初始值。这是目前的最佳实践。
三、Batch Normalization
1、Batch Normalization 的算法
Batch Norm 的优点
- 可以使学习快速进行(可以增大学习率)。
- 不那么依赖初始值(对于初始值不用那么神经质)。
- 抑制过拟合(降低 Dropout 等的必要性)。
如前所述,Batch Norm 的思路是调整各层的激活值分布使其拥有适当的广度。为此,要向神经网络中插入对数据分布进行正规化的层,即 Batch Normalization 层(下文简称 Batch Norm 层),如图 6-16 所示。
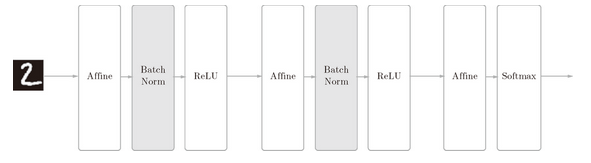
图 6-16 使用了 Batch Normalization 的神经网络的例子(Batch Norm 层的背景为灰色)
Batch Norm,顾名思义,以进行学习时的 mini-batch 为单位,按 mini-batch 进行正规化。具体而言,就是进行使数据分布的均值为 0、方差为 1 的正规化。用数学式表示的话,如下所示。
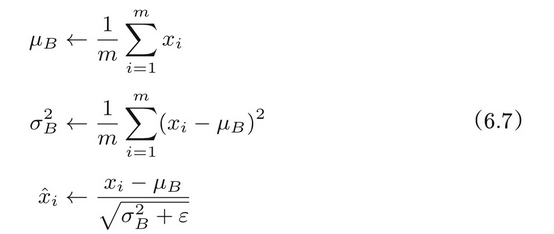
这里对 mini-batch 的 m 个输入数据的集合 B={ x1, x2···, xm}求均值 和方差
。然后,对输入数据进行均值为 0、方差为 1(合适的分布)的正规化。式(6.7)中的 ε 是一个微小值(比如,
10e-7 等),它是为了防止出现除以 0 的情况。
接着,Batch Norm 层会对正规化后的数据进行缩放和平移的变换,用数学式可以如下表示。
这里,γ 和 β 是参数。一开始 γ = 1,β = 0,然后再通过学习调整到合适的值。
上面就是 Batch Norm 的算法。这个算法是神经网络上的正向传播。如果使用第 5 章介绍的计算图,Batch Norm 可以表示为图 6-17。
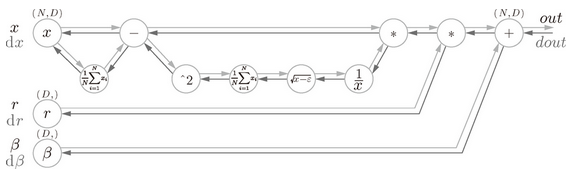
图 6-17 Batch Normalization 的计算图
2、Batch Normalization的评估
略